
ideyaLabs gives a holistic strategy to information engineering and analytics that covers all the technical drivers required to entirely capitalize on your agency facts resources.
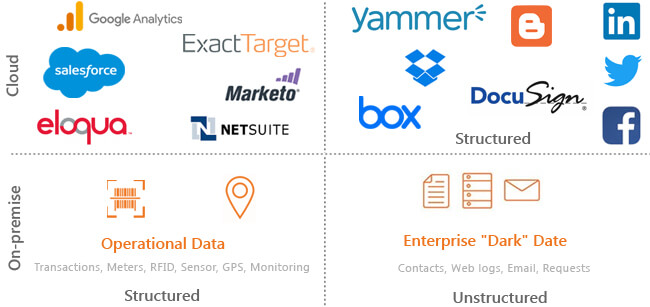
Enterprises have get admission to to masses of data, however most goes unused
It comes in all shapes and sizes — each structured and unstructured types that encompass structures of engagement, structures of document and social media.
We have constructed skills round Big Data platform implementation from ETL, records processing, compute, records orchestration, visualization, reporting, analytics, advanced, predictive analytics, statistics modeling and information science. Leveraging these capabilities, we provide End-to-End Big Data and Data Engineering services.
We assist agencies to decide their massive records approach and seek advice from on enhancing the enterprise overall performance uncovering the energy of data. Our Big Data consulting consists of POC/POV, technical recommendations, information supply analysis, architectural consulting, capability planning and lots more.
We can assist groups with real-time information ingestion, ETL & batch processing and storage from one of a kind & complicated records sources leveraging our deep know-how throughout huge facts applied sciences such as Hadoop (HDFS, Map Reduce, Hive, Flume, Sqoop and Oozie) and Spark. We assist corporations create real-time charts & dashboards and setup pipeline.
We use a variety of equipment such as Tableau, Chart.js, Dygraphs, D3JS and High Charts to produce visuals and tales that generate excessive commercial enterprise impact. We generate customized dashboards, reports, indicators and metrics as per commercial enterprise good judgment and observe computing device studying algorithms & records modeling to function predictive evaluation the use of strategies such as regression and choice trees.
We assist agencies design, architect and enforce records lake frameworks and combine information property to derive significant insights barring any information loss. The implementation consists of figuring out records channels, facts integration, backup, archive, facts processing, facts orchestration and visualization alongside with information governance and automation.
Leveraging our know-how in each DevOps and Big Data Administration, we make sure structure setup, implementation with full automation and manipulate the typical overall performance of Hadoop clusters to make certain excessive throughput and availability. We additionally assist corporations become aware of achievable threats through, facts governance and get admission to & identification administration to assist make certain facts security.
We make sure information quality, accuracy, consistency and completeness via huge records trying out and automation. Our QA Engineers verify records in a 3stage validation along with statistics stage validation, MapReduce Validation and output validation accompanied with overall performance trying out of huge facts applications.
We leverage fantastic enterprise equipment & software program frameworks to store, process, analyze and visualize your data.



















